Unity-Technologies/ml-agents
Unity Machine Learning Agents Toolkit. Contribute to Unity-Technologies/ml-agents development by creating an account on GitHub.
github.com
ML-Agents의 사용방법에 조금 익숙해질 겸 Example에 있는 예제 하나를 직접 구현해봤다.
예시는 큰 공을 찾아가는 박스를 만드는 것인데 이것을 응용하는 방식으로 만들어 보려고 한다.
(강화 학습에 대한 아주 기본적인 지식만 가지고 점점 배워가는 것이 목표이다.)

학습을 진행하기 위해서는 위 Github 페이지에서 받은 ML-Agents 프로젝트 내부에 현재 프로젝트가 위치해야 한다.
기본 프로젝트를 생성하고 아래 이미지처럼 바닥을 생성하고 3D Ball 하나를 추가한다.


학습을 진행하기 이전에 Academy를 생성해야 한다.
Empty Object를 생성하고 Academy 이름을 변경, BasicExampleAcademy 스크립트를 추가해준다.

using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using MLAgents;
public class BasicExampleAcademy : Academy
{
public override void AcademyReset()
{
}
public override void AcademyStep()
{
}
}
이후에 목표로 설정할 Target 오브젝트들을 만들어준다.
학습 목표는 4개의 랜덤 한 기둥 중 한 개의 높이가 커지는데 공이 이 기둥을 찾아가게 만드는 것이 목표이다.

그리고 학습에 사용할 Brain을 추가해준다.

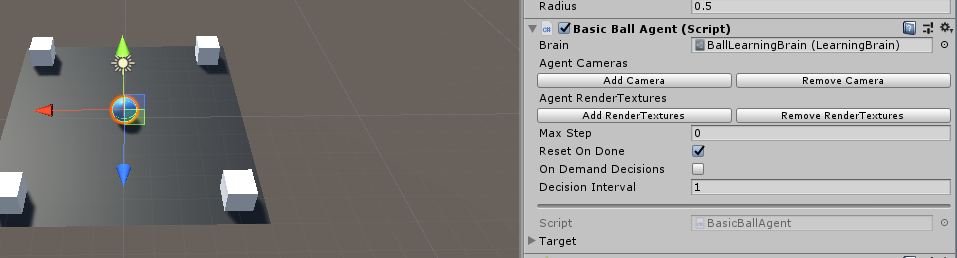
다음으로는 가장 중요한 Agent에 대한 설정이다.
공을 선택하고 BasicBallAgent 스크립트를 추가한다.
아래 스크립트를 작성하면 위에서 생성한 Brain을 Agent에 추가할 수 있다.
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using MLAgents;
public class BasicBallAgent : Agent
{
private Rigidbody ballRb;
public GameObject[] target;
private Vector3 beforePos;
private float beforeDistance = 9999;
private int targetIdx = -1;
public override void InitializeAgent()
{
ballRb = GetComponent<Rigidbody>();
MakeRandomTarget();
}
public override void CollectObservations()
{
AddVectorObs(gameObject.transform.position);
AddVectorObs(target[targetIdx].transform.position);
AddVectorObs(ballRb.velocity.x);
AddVectorObs(ballRb.velocity.z);
}
public override void AgentAction(float[] vectorAction, string textAction)
{
Vector3 velocity = Vector3.zero;
velocity.x = vectorAction[0];
velocity.z = vectorAction[1];
ballRb.AddForce(velocity * 10);
float distanceToTarget = Vector3.Distance(gameObject.transform.position, target[targetIdx].transform.position);
/*
if (beforeDistance > distanceToTarget)
{
AddReward(0.001f);
}
beforeDistance = distanceToTarget;
*/
if (distanceToTarget < 1.5f)
{
AddReward(1.0f);
MakeRandomTarget();
Done();
}
if (gameObject.transform.position.y < 0)
{
AddReward(-1f);
Done();
}
}
public override void AgentReset()
{
if (this.transform.position.y < 0)
{
this.transform.position = new Vector3(0, 0, 0);
this.ballRb.angularVelocity = Vector3.zero;
this.ballRb.velocity = Vector3.zero;
}
}
void MakeRandomTarget()
{
beforeDistance = 9999;
if (targetIdx != -1)
{
beforePos = target[targetIdx].transform.position;
beforePos.y = 0.5f;
target[targetIdx].transform.position = beforePos;
target[targetIdx].transform.localScale = new Vector3(1, 1, 1);
}
targetIdx = Random.Range(0, 4);
beforePos = target[targetIdx].transform.position;
beforePos.y = 1f;
target[targetIdx].transform.position = beforePos;
target[targetIdx].transform.localScale = new Vector3(1, 2, 1);
}
/*
private void FixedUpdate()
{
AddReward(-0.001f);
}
*/
}
Unity-Technologies/ml-agents
Unity Machine Learning Agents Toolkit. Contribute to Unity-Technologies/ml-agents development by creating an account on GitHub.
github.com
학습 방법에 대한 내용은 위 페이지에서 자세하게 안내하고 있다.
(추가적인 세팅에 대한 내용은 추후에 포스팅하려고 한다.)
현재까지 이해한 부분에 대해서 간략하게 설명하자면
아래의 메서드들은 ML-Agents에 구현된 것을 override 해서 구현하고 있다.
1.
InitializeAgent는 말 그대로 Agent를 초기화하는 역할을 하고 있다.
4개의 타깃 중 1개를 랜덤으로 선택하여 높이값을 변경한다.
2.
CollectObservations는 Agent의 행동 이후에 학습에 사용할
값 들을 넘겨주게 되면 이것들을 사용하여 학습을 수행한다.
Agent의 위치와 높이가 다른 타깃의 위치
그리고 Agent의 x, z축의 속도 값을 학습하는 데 사용한다.
3.
AgentAction의 파라미터인 vectionAction으로 인공지능이 명령을 내리게 된다.
현재 사용하는 값은 CollectObservations에서 설정한 것 과 같은 x, z 축에 대한 속도 값이다.
AgentAction 메서드에서 Agent의 동작에 변화에 대한 작업을 수행하고 있다.
그리고 Agent의 행동에 따른 보상, 페널티를 주게 되는데
높이가 다른 설정한 타깃에 닿으면 1점의 보상을 지급하고
임의의 새로운 타깃을 생성, 현재 단계의 학습을 마무리하게 된다.
Agent가 바닥에서 떨어지는 경우 -1점의 페널티를 부과하고
현재 단계의 학습을 마무리하게 된다.
(주석 부분의 경우 아래에서 추가로 설명한다.)
4.
AgentAction에서 현재 단계의 학습이 마무리가 되면
AgentReset에서 Agent를 초기화하게 된다.
현재 설정한 초기화 작업은 Agent가 바닥에서 떨어지는 경우
원점의 위치에 모든 속도 값이 초기화된 상태로 다시 설정을 하게 된다.
public override void InitializeAgent()
{
ballRb = GetComponent<Rigidbody>();
MakeRandomTarget();
}
public override void CollectObservations()
{
AddVectorObs(gameObject.transform.position);
AddVectorObs(target[targetIdx].transform.position);
AddVectorObs(ballRb.velocity.x);
AddVectorObs(ballRb.velocity.z);
}
public override void AgentAction(float[] vectorAction, string textAction)
{
Vector3 velocity = Vector3.zero;
velocity.x = vectorAction[0];
velocity.z = vectorAction[1];
ballRb.AddForce(velocity * 10);
float distanceToTarget = Vector3.Distance(gameObject.transform.position, target[targetIdx].transform.position);
/*
if (beforeDistance > distanceToTarget)
{
AddReward(0.001f);
}
beforeDistance = distanceToTarget;
*/
if (distanceToTarget < 1.5f)
{
AddReward(1.0f);
MakeRandomTarget();
Done();
}
if (gameObject.transform.position.y < 0)
{
AddReward(-1f);
Done();
}
}
public override void AgentReset()
{
if (this.transform.position.y < 0)
{
this.transform.position = new Vector3(0, 0, 0);
this.ballRb.angularVelocity = Vector3.zero;
this.ballRb.velocity = Vector3.zero;
}
}
학습을 진행하기에 앞서 아까 생성한 BallLearningBrain 설정을 변경해야 한다.
CollectObservations에서 AddVectorObs로 넘겨주는 값에 대한 설정이다.
x, y, z로 이루어진 Agent와 타깃의 벡터가 각각 존재하므로 = 6개
x, z 방향의 단일 속도 값이 각각 있으므로 = 2개
총 8개의 파라미터를 넘겨주게 된다.
그래서 아래와 같이 Vector Observation의 Space Size는 8개이고
Vector Action에서 Type을 Continuous로 변경하고
Space Size는 x, z의 속도 값들의 개수 2개를 입력한다.


이제 드디어 학습을 진행하게 된다.

시간이 지날수록 점점 더 잘 찾아가기 시작한다.

시간이 지나다가 나아질 기미가 보이지 않고
이상하게 동작한다면 Agent 세팅을 다시 해야 할 수도 있다.

이렇게 학습을 돌려놓고 오랜 시간 학습하면 더 좋은 결과가 있을 것 같아서
자고 일어났더니 더 이상한 결과가 나타났다.
학습한 모델을 이용하여 플레이를 했는데 Agent가 미동도 하지 않는 모습이다.
오랜 학습 끝에 판단한 최적의 결과가 가만히 있기라는 게 상당히 재미있었다.

이러한 결과가 원하는 방향은 아니라서 새로운 규칙을 추가했다.
(위 코드에서 주석 처리한 부분)
private void FixedUpdate()
{
AddReward(-0.001f);
}
계속해서 소량의 페널티를 주도록 로직을 추가했다.
이렇게 하면 Reward를 최대로 획득하기 위해서 열심히
행동을 할 것이라는 생각으로 추가했다.
학습을 중간에 중단시키거나 완전히 마무리가 된 경우
ML-Agents -> models 폴더네 학습이 완료된 모델 파일이 저장되어 있다.
이렇게 학습된 모델을 BallLearningBrain에 추가하면
학습된 인공지능이 Agent를 조종하게 된다.

인공지능이 직접 움직이는 Agent의 모습으로
임의로 타깃을 움직이는 돌발상황이 발생해도 잘 따라오는 모습을 보여준다.

PuzzleLeaf/ml-agent-tutorial
Contribute to PuzzleLeaf/ml-agent-tutorial development by creating an account on GitHub.
github.com
'Unity' 카테고리의 다른 글
| [Unity] ml-agents 설치하기 및 테스트 (0) | 2020.01.19 |
|---|---|
| [Unity] 퍼포 더 코기 (ML-Agents) 강화학습 공부 (0) | 2019.05.26 |

